1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
| import requests
from bs4 import BeautifulSoup
def scrape_news(url):
response = requests.get(url)
response.encoding = "utf-8"
soup = BeautifulSoup(response.text, "html.parser")
body = soup.body
if body is not None:
div = body.find("div", class_="wrap")
if div is not None:
div_container = div.find("div", class_="container clearfix")
if div_container is not None:
div_pull_right = div_container.find(
"div", class_="pull-right list-right"
)
if div_pull_right is not None:
lb_ul = div_pull_right.find("ul", class_="lb-ul")
if lb_ul is not None:
li = lb_ul.find_all("li")
result = ""
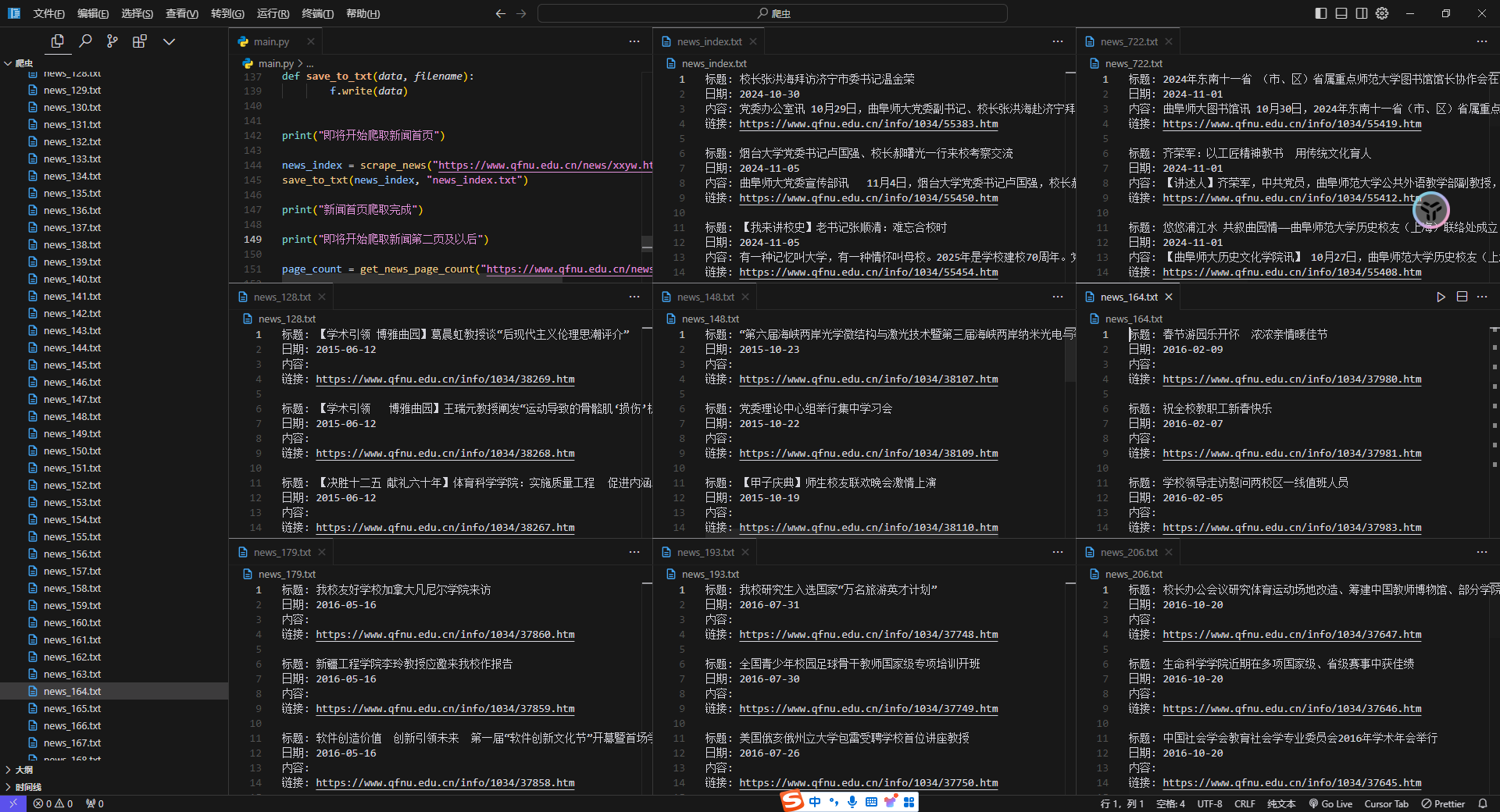
for item in li:
title = item.find("div", class_="lb-ul-tt txt-elise").text
date = item.find("div", class_="lb-ul-date").text
content = item.find("div", class_="lb-ul-p").text
link = item.find("a", class_="clearfix img-hide").get(
"href"
)
link = (
f"https://www.qfnu.edu.cn{link[2:].replace("../", "")}"
)
result += f"标题: {title}\n日期: {date}\n内容: {content}\n链接: {link}\n\n"
return result
else:
print(f"未找到 class 为 'lb-ul' 的 ul,获取到的值是:{lb_ul}")
return
else:
print(
f"未找到 class 为 'pull-right list-right' 的 div,获取到的值是:{div_pull_right}"
)
return
else:
print(
f"未找到 class 为 'container clearfix' 的 div,获取到的值是:{div_container}"
)
return
else:
print(f"未找到 class 为 'wrap' 的 div,获取到的值是:{div}")
return
else:
print(f"未找到 body,获取到的值是:{body}")
return
def get_news_page_count(url):
response = requests.get(url)
response.encoding = "utf-8"
soup = BeautifulSoup(response.text, "html.parser")
body = soup.body
if body is not None:
div = body.find("div", class_="wrap")
if div is not None:
div_container = div.find("div", class_="container clearfix")
if div_container is not None:
div_pull_right = div_container.find(
"div", class_="pull-right list-right"
)
if div_pull_right is not None:
div_page_box = div_pull_right.find(
"div", class_="page-box text-center wow fadeInUp"
)
if div_page_box is not None:
div_pb_sys_common = div_page_box.find(
"div", class_="pb_sys_common"
)
if div_pb_sys_common is not None:
span_p_pages = div_pb_sys_common.find(
"span", class_="p_pages"
)
if span_p_pages is not None:
span_p_no = span_p_pages.find("span", class_="p_no")
if span_p_no is not None:
a = span_p_no.find("a")
if a is not None:
return int(
a.get("href")
.replace(".htm", "")
.replace("xxyw/", "")
)
else:
print(
f"未找到 class 为 'pb_sys_common' 的 div,获取到的值是:{div_pb_sys_common}"
)
return 0
else:
print(
f"未找到 class 为 'page-box text-center wow fadeInUp animated' 的 div,获取到的值是:{div_page_box}"
)
return 0
else:
print(
f"未找到 class 为 'pull-right list-right' 的 div,获取到的值是:{div_pull_right}"
)
return 0
else:
print(
f"未找到 class 为 'container clearfix' 的 div,获取到的值是:{div_container}"
)
return 0
else:
print(f"未找到 class 为 'wrap' 的 div,获取到的值是:{div}")
return 0
else:
print(f"未找到 body,获取到的值是:{body}")
return 0
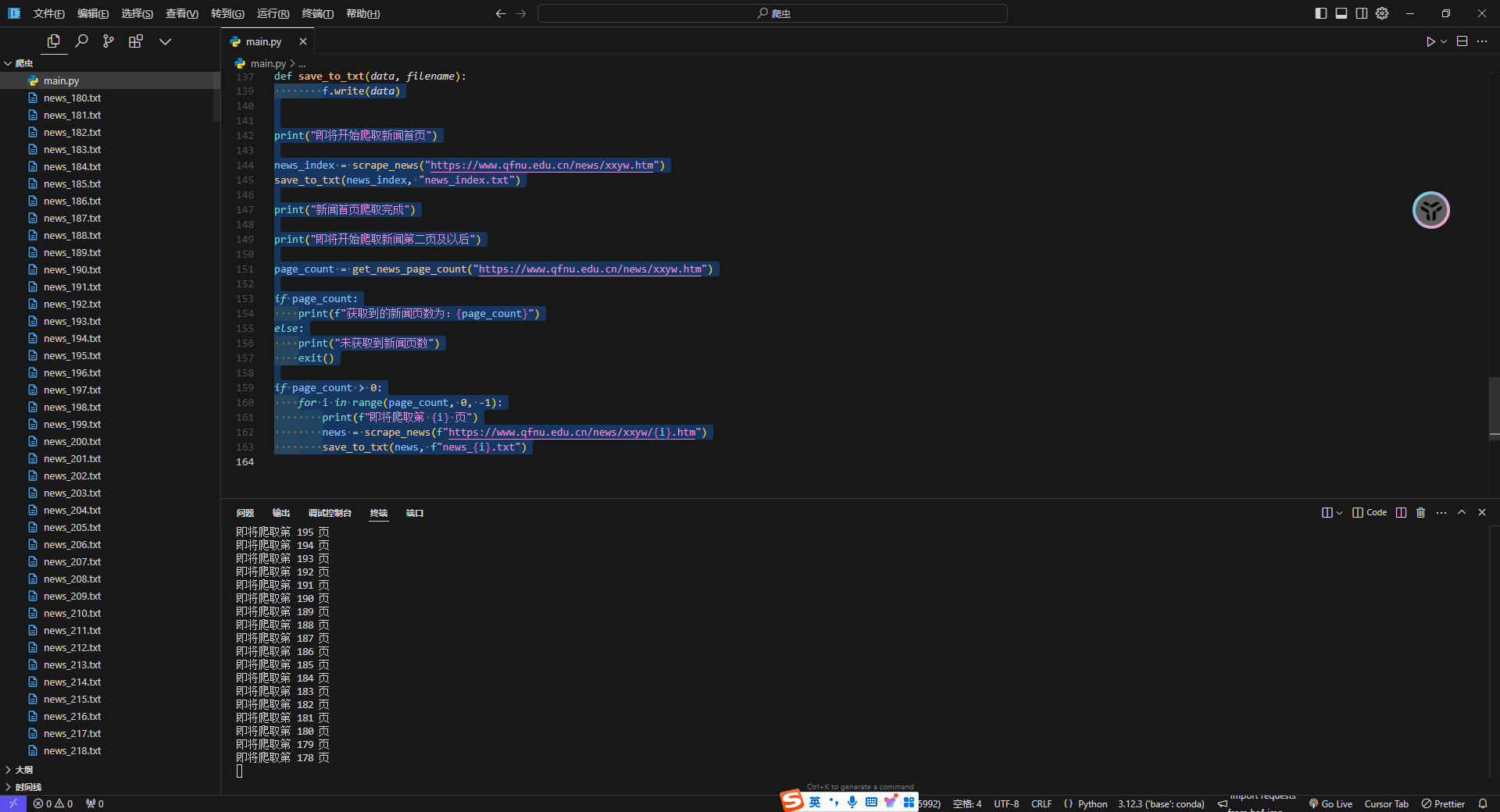
def save_to_txt(data, filename):
with open(filename, "w", encoding="utf-8") as f:
f.write(data)
print("即将开始爬取新闻首页")
news_index = scrape_news("https://www.qfnu.edu.cn/news/xxyw.htm")
save_to_txt(news_index, "news_index.txt")
print("新闻首页爬取完成")
print("即将开始爬取新闻第二页及以后")
page_count = get_news_page_count("https://www.qfnu.edu.cn/news/xxyw.htm")
if page_count:
print(f"获取到的新闻页数为:{page_count}")
else:
print("未获取到新闻页数")
exit()
if page_count > 0:
for i in range(page_count, 0, -1):
print(f"即将爬取第 {i} 页")
news = scrape_news(f"https://www.qfnu.edu.cn/news/xxyw/{i}.htm")
save_to_txt(news, f"news_{i}.txt")
|