
Python爬虫、自动化脚本与QQ机器人

安全声明
重要: 本课程内容仅限于学习、研究和技术交流目的,在 授权或公开 的网络资源上进行测试。
- 请勿 对未授权的网站或系统进行爬取或自动化操作。
- 请勿 将所学技术用于任何非法用途或商业牟利。
- 请遵守 目标网站的
robots.txt协议和用户协议。 - 合理控制 请求频率,避免对目标服务器造成过大负担。(DDoS 攻击)
任何滥用技术导致的法律责任或后果,均由使用者自行承担。
引言:我们今天要探讨什么?
- Python 爬虫 (Web Crawler/Spider): 自动获取网络信息的“数据矿工”。
- 自动化脚本 (Automation Script/Bot): 模拟人类操作的“智能助手”。
- 它们之间的联系与区别。
- 为什么 Python 是实现这些功能的有力工具?
什么是 Python 爬虫?
定义: 使用 Python 编程语言编写的、用于 自动、系统性地 从互联网上 获取(抓取) 网页信息的程序或脚本。
- 想象一下“网络蜘蛛”(Spider)在“万维网”(Web)上按照一定规则爬行,收集信息。
主要目的:
- 数据采集: 如市场价格、新闻资讯、用户评论等。
- 信息整合: 如聚合内容、制作索引(搜索引擎核心)。
- 数据分析: 为后续的数据分析、挖掘提供原始数据。
为什么用 Python?
- 语法简洁,易于上手: 开发效率高。
- 强大的第三方库生态:
requests: 方便地发送 HTTP 网络请求。BeautifulSoup,lxml: 高效地解析 HTML/XML 文档,提取数据。Scrapy: 强大的异步爬虫框架,适合大型项目。
- 活跃的社区: 容易找到学习资源和解决方案。
什么是自动化脚本?
定义: 使用编程语言(如 Python)编写的,用于 模拟人类用户 与计算机系统(尤其是 Web 界面)进行交互,以 自动完成特定、重复性任务 的程序。
主要目的:
- 任务自动化: 替代手动执行繁琐、耗时的操作。
- 效率提升: 例如,在特定时间点快速完成抢课、抢票、签到等。
- 流程执行: 自动登录、填写表单、点击按钮、提交数据等。
与爬虫的联系:
- 通常也需要与 Web 服务器进行交互(发送请求、接收响应)。
- 可能使用与爬虫相同的库(如
requests,Selenium)。 Selenium这类浏览器自动化工具在复杂交互脚本中尤其常用。
爬虫 vs. 自动化脚本:核心区别
| 特性 | Python 爬虫 | 自动化脚本 (Bot) |
|---|---|---|
| 核心目标 | 数据获取 (Information Retrieval) | 任务执行 (Task Execution) |
| 主要操作 | 读取网页内容 (Read) | 模拟用户交互 (Interact/Write) |
| 范围 | 通常较广,可能遍历多个页面/网站 | 通常较窄,针对特定流程/任务 |
| 侧重点 | 高效下载、解析、存储数据 | 精确模拟操作、处理登录状态、提交数据 |
简单来说:爬虫侧重于“看”和“存”,自动化脚本侧重于“做”和“交互”。
Python 爬虫案例演示
由于之前学期大家都选修了 Python 课程,期末大作业就是爬虫作业,这里不过多解释
Python 自动化脚本案例演示——以学校某系统为例
核心知识点
涉及的关键知识点:
- HTTP 基础:
- 理解 GET 和 POST 请求的区别。
- 了解请求头 (Headers)、Cookies、表单数据 (Form Data) 的作用。
- 浏览器开发者工具 (F12):
- 元素审查 (Inspect Element): 定位 HTML 元素,获取其 ID, Name, Class, XPath, CSS Selector 等定位符。
- 网络分析 (Network Tab): 查看实际的网络请求过程(URL, 请求方法, Headers, Payload, 响应内容),分析登录、提交等关键操作的请求细节。
- 核心 Python 库:
requests库:- 发送 GET/POST 请求 (
requests.get,requests.post)。 - 管理会话 (
requests.Session) 以保持登录状态 (自动处理 Cookies)。 - 定制请求头 (Headers)。
- 提交表单数据。
- 发送 GET/POST 请求 (
Selenium库 (用于复杂交互或 JavaScript 渲染页面):- WebDriver 的安装与配置 (如 ChromeDriver)。
- 启动和控制浏览器 (
webdriver.Chrome())。 - 定位页面元素 (
find_element)。 - 模拟用户操作 (输入
send_keys, 点击click, 选择下拉框等)。 - 处理页面等待 (
implicitly_wait,WebDriverWait,expected_conditions)。 - 执行 JavaScript 脚本 (
execute_script)。
- HTML/XML 解析 (可选,若需从页面提取信息):
BeautifulSoup或lxml: 解析requests获取的 HTML 内容,或Selenium获取的page_source,提取状态信息或下一步操作所需数据。
- 登录与认证处理:
- 分析登录请求 (通常是 POST 请求)。
- 构造登录所需的表单数据。
- 处理验证码 (简单的图形验证码可尝试 OCR 库如
ddddocr,复杂的交互式验证码是难点)。
- 模拟操作流程:
- 根据手动操作步骤,将每一步转化为代码实现 (访问特定 URL、填写表单、点击按钮)。
- 处理页面跳转和导航逻辑。
- 异常处理:
- 使用
try...except语句处理网络错误、元素找不到、登录失败等异常情况,增强脚本健壮性。
- 使用
- 配置与参数化:
- 将用户名、密码、目标 URL 等信息存储在配置文件或变量中,而不是硬编码在代码里。
- 频率控制与道德规范:
- 使用
time.sleep()添加适当延时,避免对服务器造成过大压力。 - 再次强调遵守学校系统使用规定。
- 使用
案例 1——教务处公告监控
以 通知(旧)-曲阜师范大学教务处 为例
要想监控教务处公告,首先进入到教务处公告页面
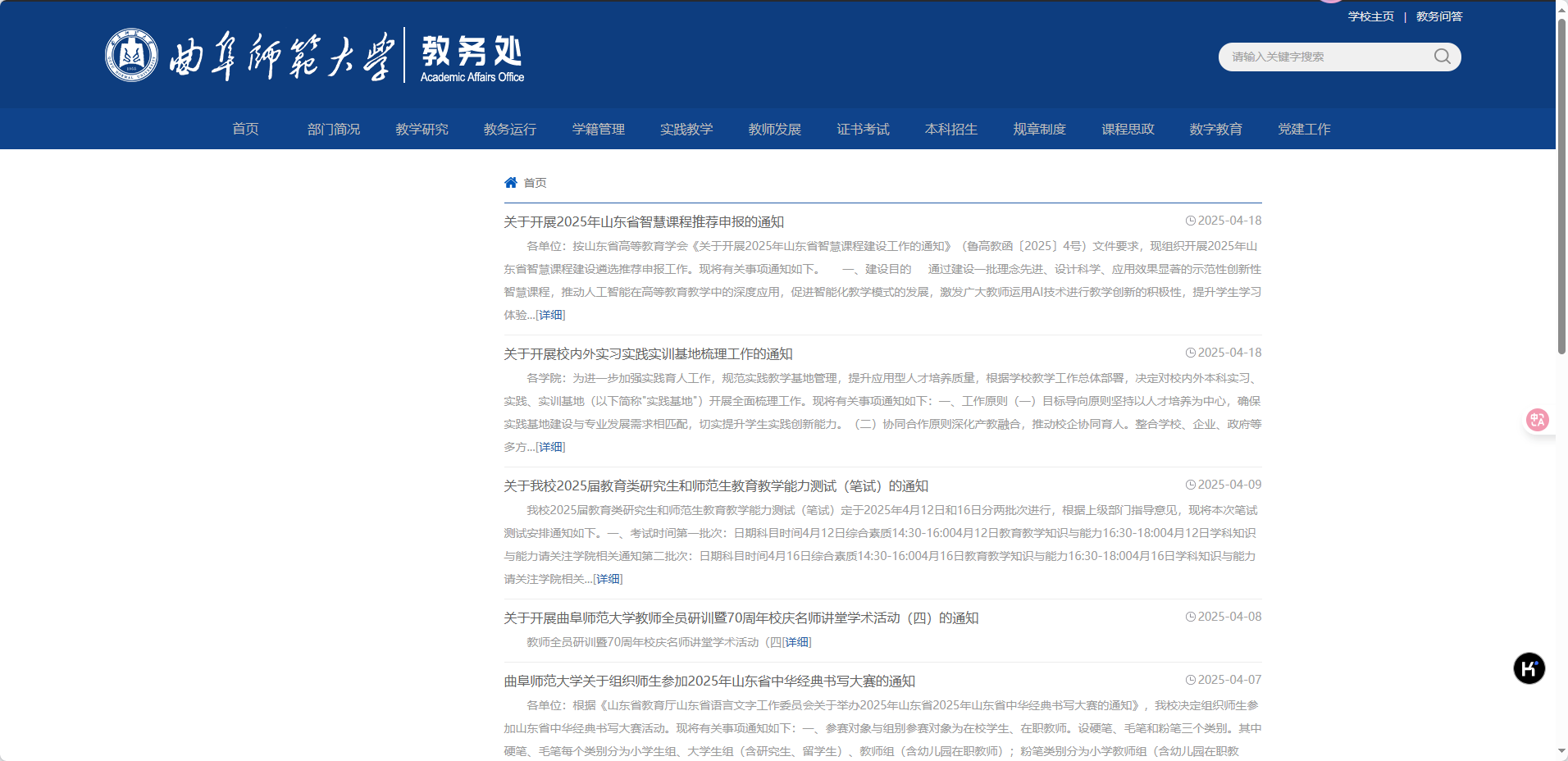
打开 F12 元素审查,可以定位到公告的主体元素
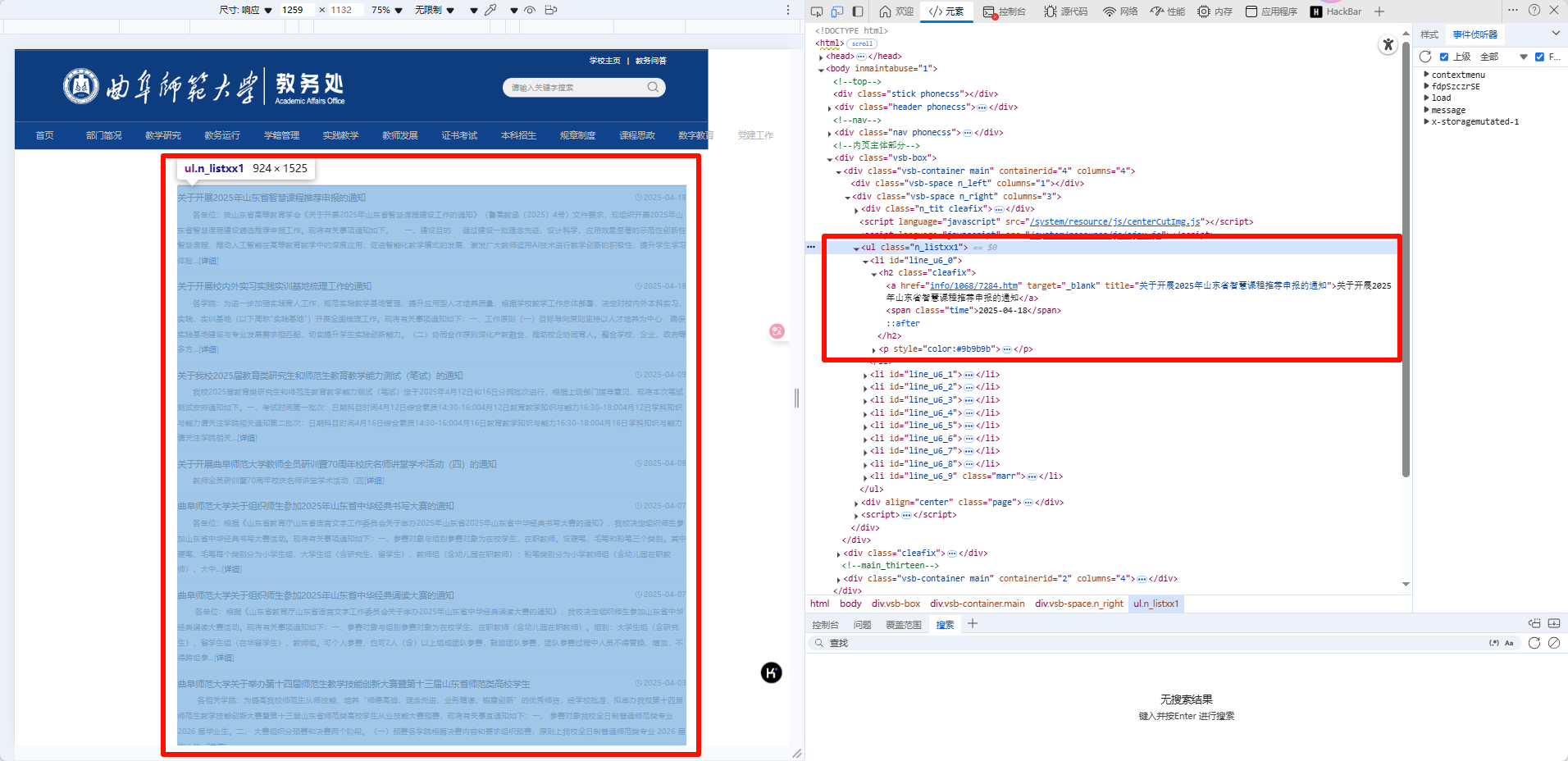
接下来就有思路了,我们可以每隔一段时间,运行脚本,获取并保存这部分元素的内容,当检测到获取的内容和保存的内容有变化,这时候就说明教务处有新内容了
借助 requests 库,我们可以很方便地发送 HTTP 请求,获取网页内容,然后使用 BeautifulSoup 库解析网页内容,提取出公告的主体元素
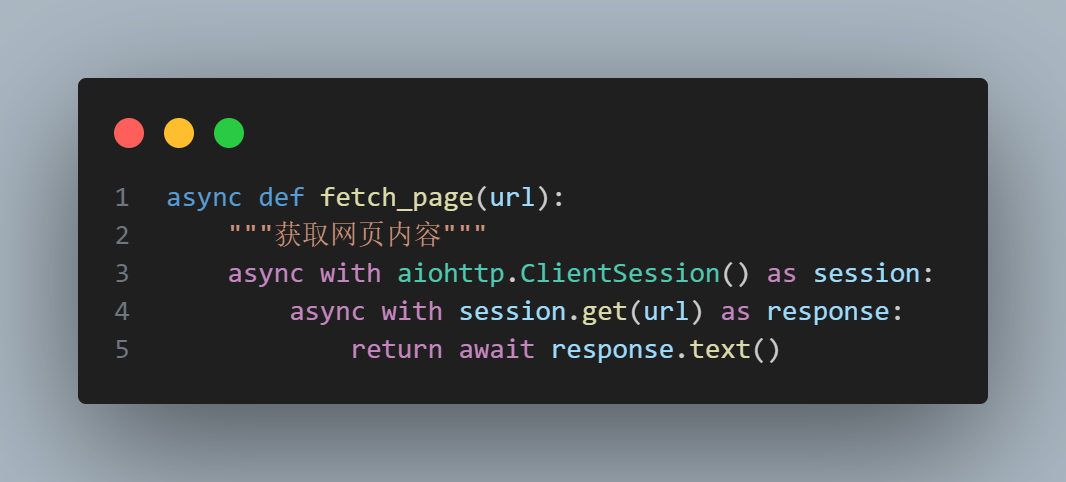
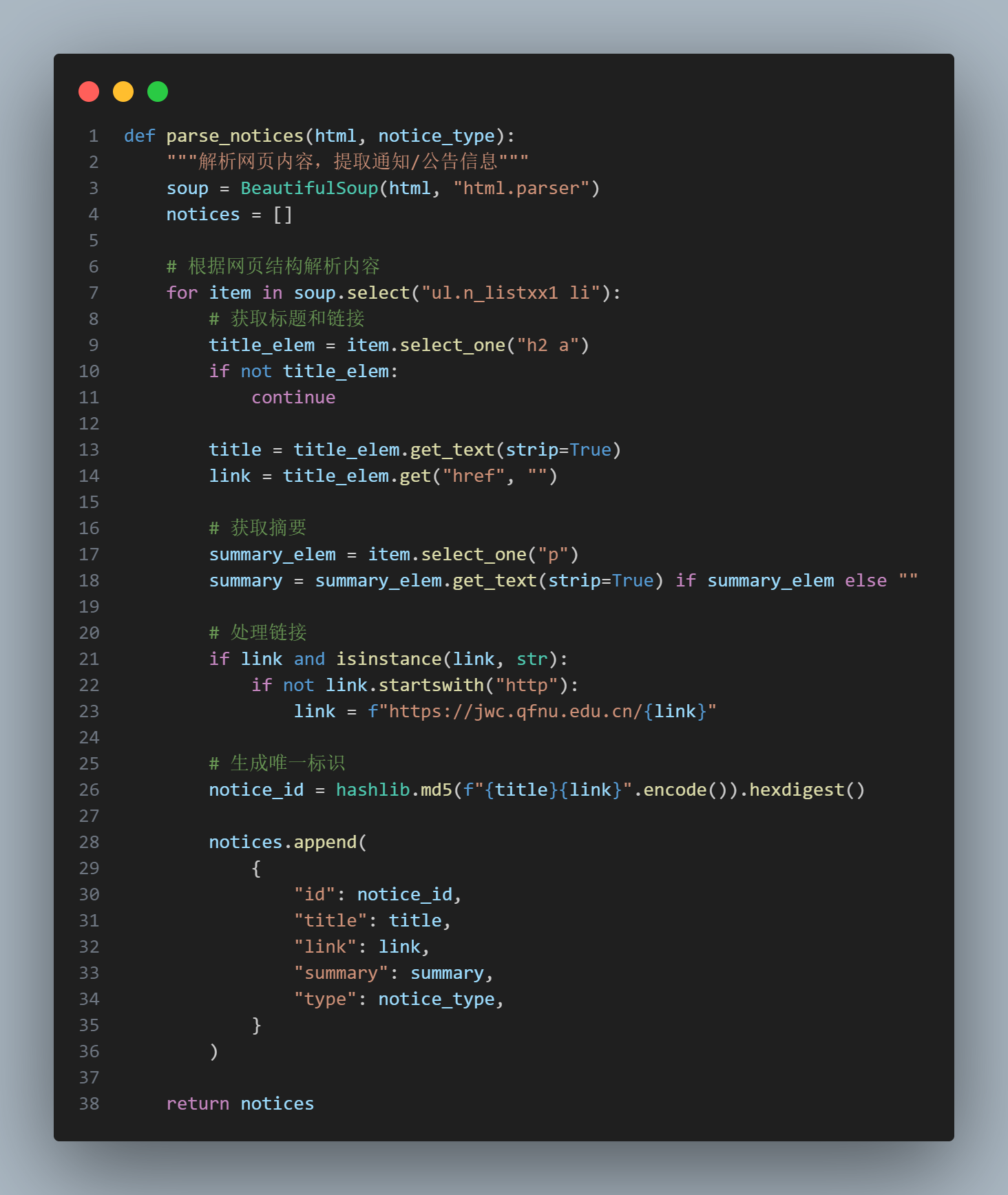
监控已经有了,如何实现提醒呢,可以接入飞书机器人、钉钉机器人、QQ 机器人等主动推送

案例 2——教务系统模拟登录
以 http://zhjw.qfnu.edu.cn/jsxsd 地址为例
为什么要强调一下这个地址呢,因为教务系统写的很乱,jsxsd 这个路径有没有,直接影响验证码路径地址,直接影响登录请求
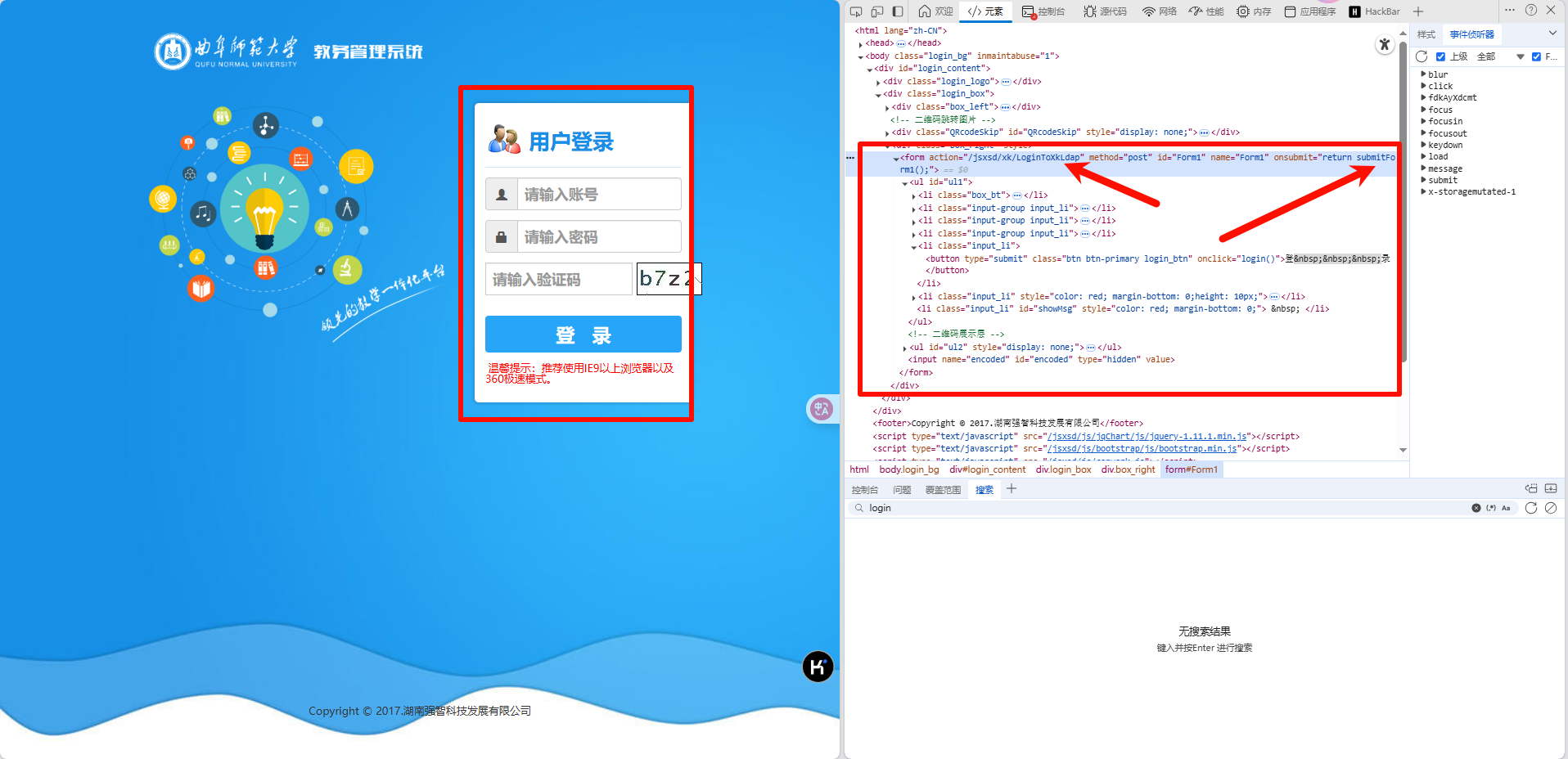
通过分析可得,登录按钮点击会触发一个 onclick 事件,按钮会调用一个 login 函数,表单会触发一个 onsubmit 事件,事件会调用一个 submitForm1 函数
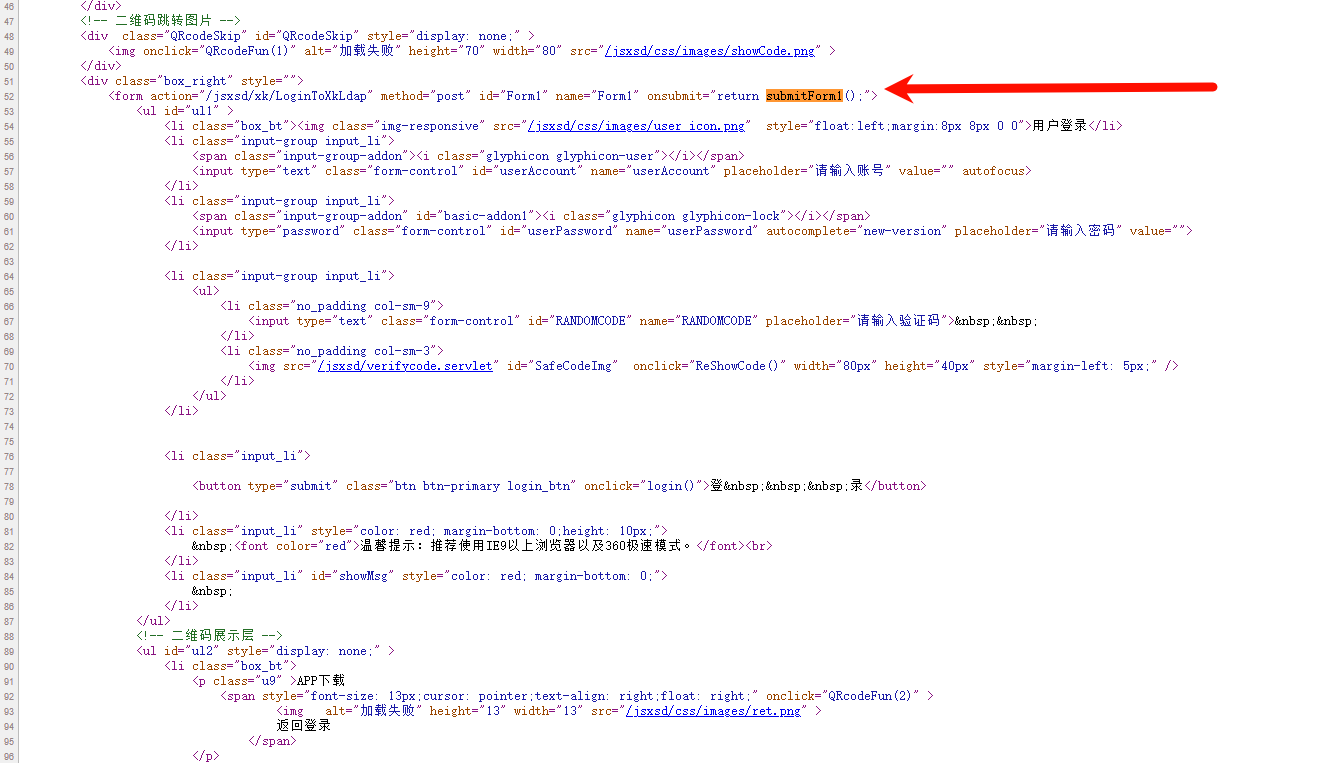
实测发现 login 这个函数不重要,他可能是与 submitForm1 协同工作的,我们只需要关注 submitForm1 函数
下面分析 submitForm1 函数

这段代码主要做了以下几件事:
- 获取用户名和密码
- 如果用户名和密码为空,则弹出提示框,并返回 false
- 如果用户名和密码不为空,则将用户名和密码进行编码,编码方式为
encodeInp函数 - 将编码后的用户名和密码存储到
encoded元素中 - 将
encoded元素的值存储到jzmmid元素中 - 清空密码框的值
- 如果
LoginToXkLdap不等于logonLdap,则清空用户名和密码框的值 - 返回 true
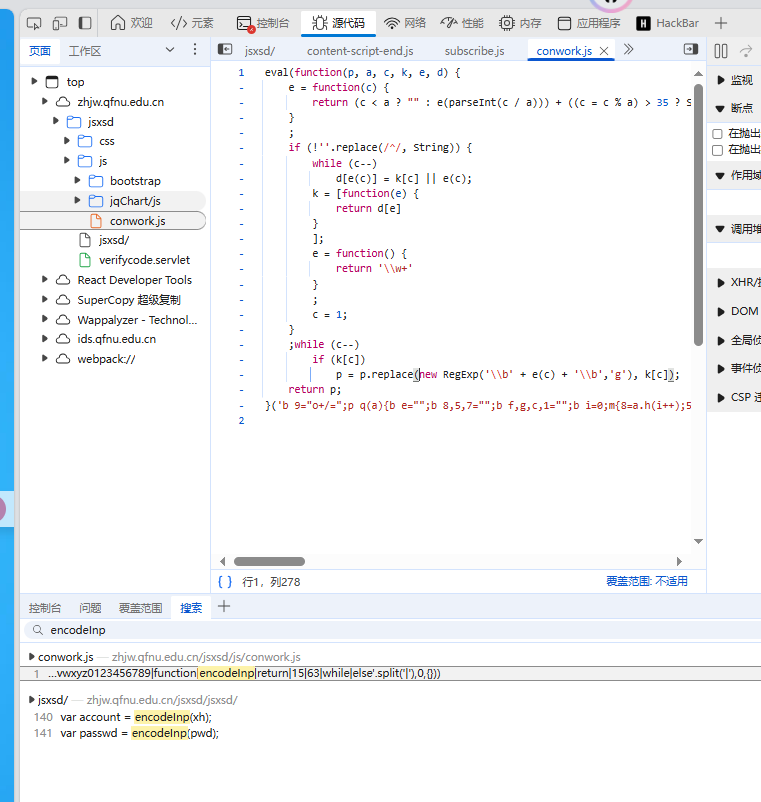
经过搜索找到了 encoded,但是代码被混淆了,反混淆之后就是一个 base64 编码,其实很简单,不反混淆也可以通过下面的抓包猜出来
原始请求包:
1 | POST /jsxsd/xk/LoginToXkLdap |
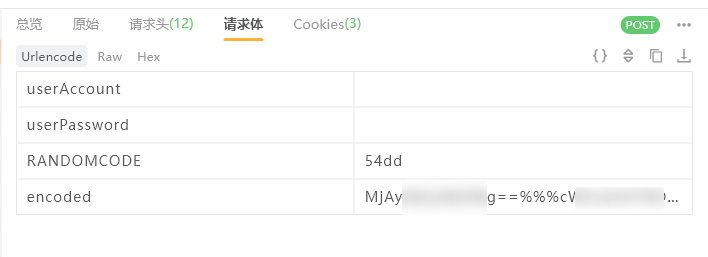
经过分析得到,userAccount 和 userPassword 是用户名和密码,RANDOMCODE 是验证码,encoded 是经过编码的用户名和密码
验证码可以通过 ddddocr 库识别,识别之后,将验证码和用户名和密码 base64 编码拼接,就可以模拟请求发送给服务器了
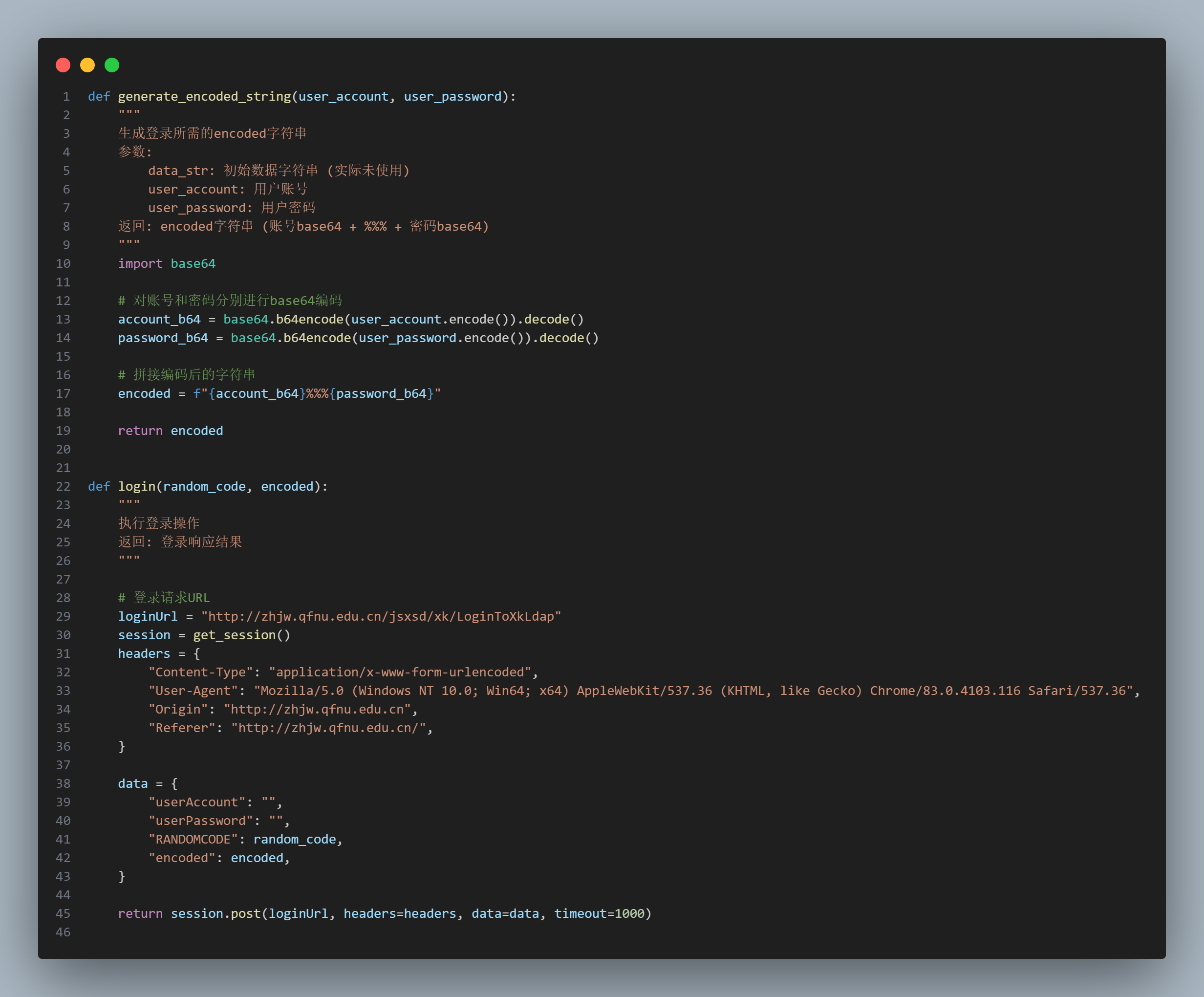
模拟登录成功之后,就可以获取到教务系统的数据了,比如课表、成绩、个人信息等,自动抢课等都是可以实现的
这个系统的代码写的很乱,一个就是一开始那个验证码的路径写了两个地方不统一,另一个就是 API 接口以及变量命名很乱,没有可读性,截取一部分代码给大家看看

案例 3——基于教务系统接入 QQ 机器人查询无课教室
由于智慧曲园的无课教室查询只有曲阜老校区,并且智慧曲园时不时还崩掉,天天进教务系统看还很麻烦,于是自己写一个接入到 QQ 里
核心思路就是利用查到的有课教室,然后从所有教室里排除有课的教室,剩下的就是无课的教室
模拟登录(案例 2 已经演示完成)
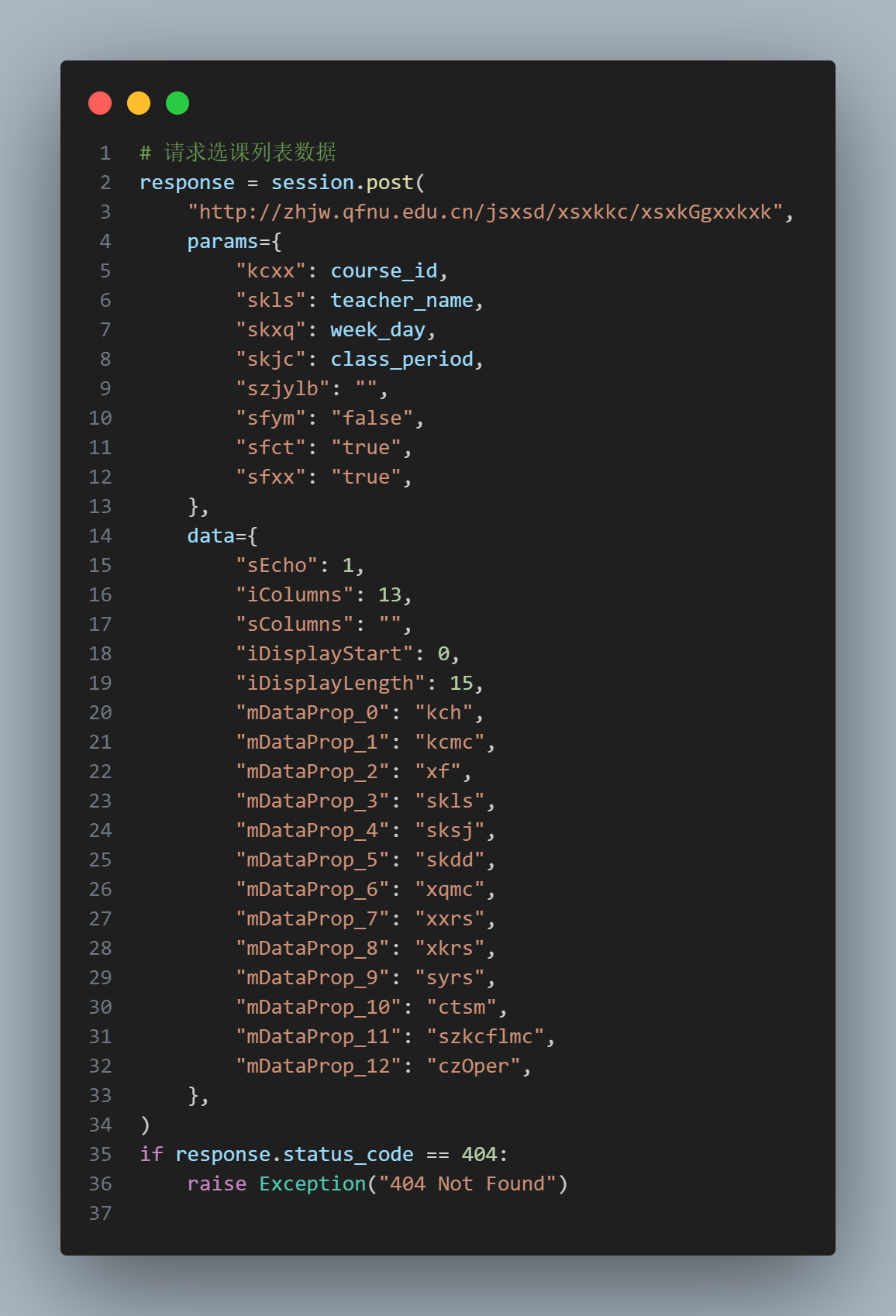
查询有课教室
通过抓包得到请求包的内容以及返回内容
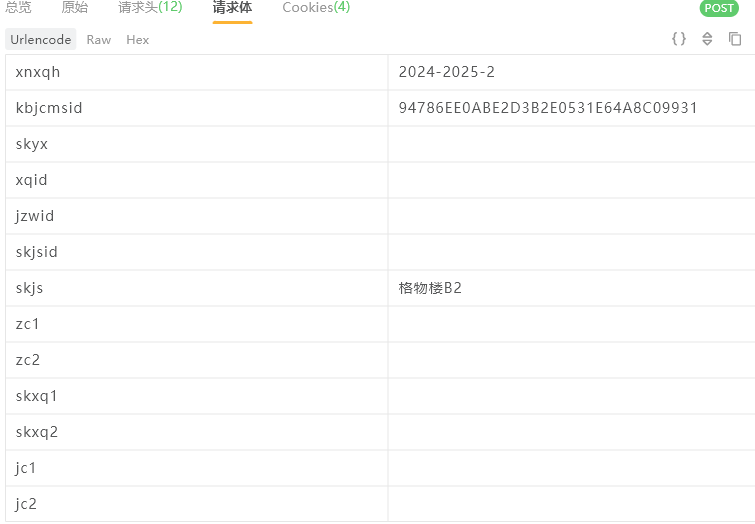

可以看到返回内容是一套 HTML,通过 BeautifulSoup 解析之后,可以得到教室列表
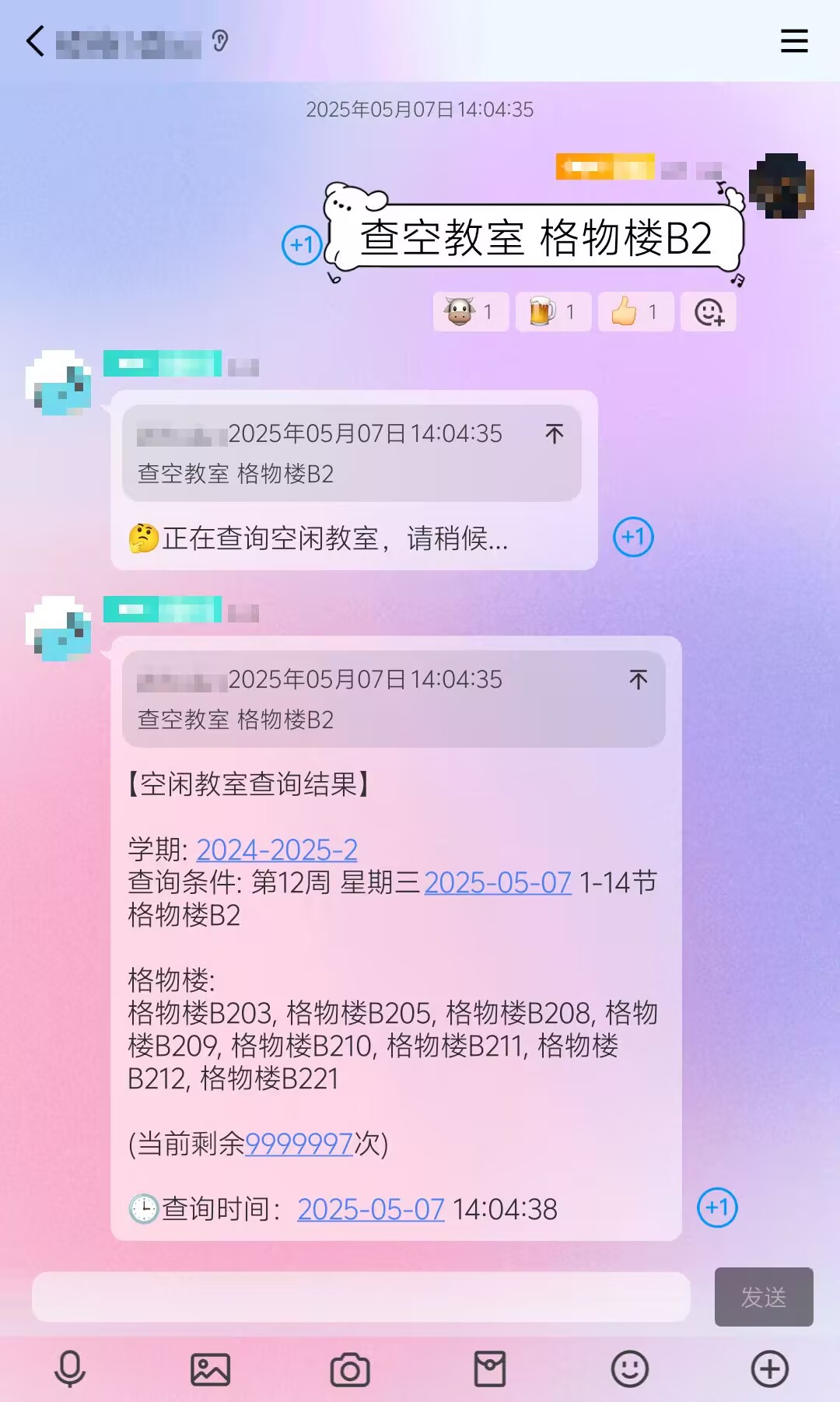
接入 QQ 机器人
接入 QQ 机器人之后就可以查无课教室了,对考研党很友好
并且我对搜索逻辑进行了优化,支持指定天数,范围节次
- 标题: Python爬虫、自动化脚本与QQ机器人
- 作者: W1ndys
- 创建于 : 2025-05-08 21:52:51
- 更新于 : 2025-10-27 19:25:00
- 链接: https://blog.w1ndys.top/posts/f6c10002.html
- 版权声明: 版权所有 © W1ndys,禁止转载。